

Her er en historisk godbit du kanskje ikke er klar over. Mellom årene 1860 og 1940, da antall metodistministre som bodde i New England økte, ble også mengden kubansk rom importert til Boston - og de økte begge på en ekstremt lignende måte. Dermed må metodistministrene ha kjøpt opp mye rom i den perioden!
Egentlig nei, det er en dum konklusjon å tegne. Det som virkelig foregår er at begge kvantiteter - metodistministre og cubanske rom - ble drevet oppover av andre faktorer, for eksempel befolkningsvekst.
Når vi har kommet fram til feil konklusjon, har vi gjort den altfor vanlige feilen til forvirrende korrelasjon med årsakssammenheng.
Hva er forskjellen?
To kvantiteter sies å være korrelert hvis begge øker og reduseres sammen ("positivt korrelert"), eller hvis en øker når den andre reduseres og vice versa ("negativt korrelert").
Korrelasjon registreres lett gjennom statistiske målinger av Pearson korrelasjonskoeffisient, som indikerer hvor tett låst sammen de to mengdene er, spenner fra -1 (helt negativt korrelert) gjennom 0 (ikke i det hele tatt korrelert) og opptil 1 (perfekt positivt korrelert).

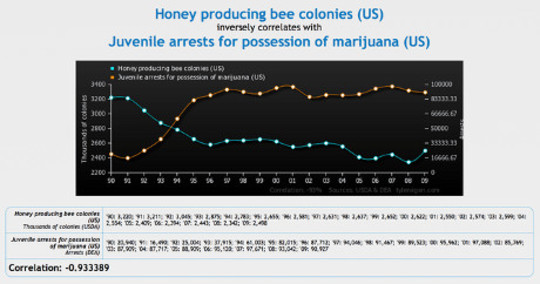
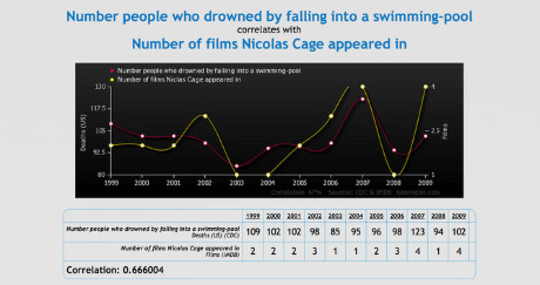 tylervigen.com
tylervigen.com
Men bare fordi to mengder er korrelerte betyr ikke nødvendigvis at man er direkte forårsaker den andre skal forandre seg. Korrelasjon innebærer ikke årsakssammenheng, akkurat som det overskyet været betyr ikke nedbør, selv om omvendt er sant.
Hvis to kvantiteter er korrelerte, kan det hende at det er en ekte årsakssammenheng (som nedbørsmengder og paraplysalg), men kanskje andre variabler kjører både (for eksempel piratnummer og global oppvarming), eller kanskje det er bare tilfeldighet (for eksempel Amerikansk ostforbruk og stryking-ved-sengetøy).
Selv der årsakssammenheng er tilstede, må vi være forsiktig med å ikke blande årsaken med effekten, ellers kan vi for eksempel konkludere at en økt bruk av varmeovner fører til kaldere vær.
For å etablere årsak og virkning må vi gå utover statistikken og se etter separate bevis (av vitenskapelig eller historisk karakter) og logisk resonnement. Korrelasjon kan be oss om å lete etter slike bevis i utgangspunktet, men det er på ingen måte et bevis i seg selv.
Subtile problemer
Selv om de ovennevnte eksemplene var åpenbart dumme, er korrelasjon ofte feilaktig for årsakssammenheng på måter som ikke er umiddelbart åpenbare i den virkelige verden. Når du leser og tolker statistikk, må du passe på å forstå nøyaktig hva dataene og statistikkene innebærer - og enda viktigere, hva de er ikke antyde.
Et nylig eksempel på behovet for forsiktighet i tolking av data er spenningen tidligere i år rundt den tilsynelatende banebrytende påvisning av gravitasjonsbølger - En kunngjøring som ser ut til å ha blitt gjort for tidlig, før alle variablene som påvirket dataene ble regnskapsført.
Dessverre er analyse av statistikk, sannsynligheter og risiko ikke et ferdighetssett som er koblet til vår menneskelig intuisjon, og det er altfor lett å bli avledet. Hele bøkene har blitt skrevet på de subtile måtene som statistikk kan misfortolkes (eller brukes til å villede). For å holde vakt opp, er det noen vanlige glatte statistiske problemer som du bør være oppmerksom på:
1) The Healthy Worker Effect, hvor noen ganger ikke to grupper kan sammenlignes direkte på like vilkår.
Vurder en hypotetisk studie som sammenligner helsen til en gruppe kontorarbeidere med helsen til en gruppe astronauter. Hvis studien ikke viser noen signifikant forskjell mellom den to-nei korrelasjonen mellom helse og arbeidsmiljø, skal vi konkludere med at det å leve og jobbe i rommet ikke har noen langsiktige helserisiko for astronautene?
Nei! Gruppene er ikke på samme nivå: astronautkorpsskjermen søker til å finne sunne kandidater, som deretter opprettholder et omfattende treningsregime for å proaktivt bekjempe effektene av å leve i "mikrogravity".
Vi vil derfor forvente at de skal være betydelig sunnere enn kontormedarbeidere, og bør med rette være bekymret hvis de ikke var det.
2) Kategorisering og scenemigreringseffekten - Shuffling mennesker mellom grupper kan ha dramatiske effekter på statistiske utfall.
Dette er også kjent som Vil Rogers effekt, etter den amerikanske komikeren som angivelig quipped:
Da Okies forlot Oklahoma og flyttet til California, reiste de det gjennomsnittlige intelligensnivået i begge statene.
For å illustrere, tenk å dele en stor gruppe venner inn i en "kort" gruppe og en "høy" gruppe (kanskje for å ordne dem for et bilde). Etter å ha gjort det, er det overraskende enkelt å øke gjennomsnittshøyden til begge gruppene samtidig.
Bare spør den korteste personen i gruppen "høy" for å bytte til "kort" gruppen. Den "høye" -gruppen mister sitt korteste medlem, og bumper dermed opp sin gjennomsnittlige høyde, men den "korte" gruppen får sitt høyeste medlem enda, og dermed også i gjennomsnittlig høyde.
Dette har store implikasjoner i medisinske studier, hvor pasienter ofte blir sortert i "sunn" eller "usunn" grupper i løpet av testingen av en ny behandling. Hvis diagnostiske metoder forbedres, kan enkelte svært lite usunn pasienter bli omkalt - noe som fører til at helseproblemene i begge gruppene forbedres, uavhengig av hvor effektiv behandling eller behandling er.
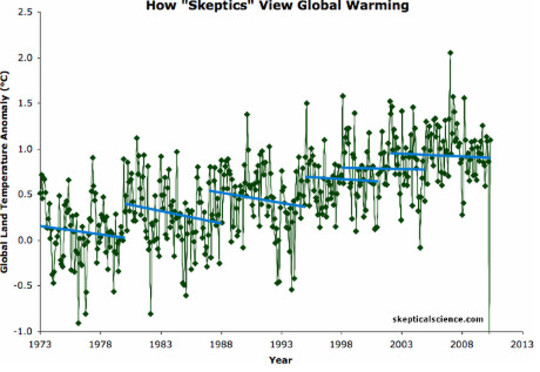 Å plukke og velge blant dataene kan føre til feil konklusjoner. Skeptikerne ser kjøleperioden (blå) når dataene virkelig viser langsiktig oppvarming (grønn). skepticalscience.com
Å plukke og velge blant dataene kan føre til feil konklusjoner. Skeptikerne ser kjøleperioden (blå) når dataene virkelig viser langsiktig oppvarming (grønn). skepticalscience.com
3) Data mining - når en overflod av data er til stede, kan biter og stykker være kirsebærplukket for å støtte enhver ønsket konklusjon.
Dette er dårlig statistisk praksis, men hvis gjort med vilje kan være vanskelig å se uten kjennskap til det opprinnelige, komplette datasettet.
Vurder grafen over som viser to tolkninger av global oppvarmingsdata, for eksempel. Eller fluor - i små mengder er det en av de mest effektive forebyggende medisinene i historien, men den positive effekten forsvinner helt hvis man bare en gang ser på giftige mengder fluor.
Av samme grunner er det viktig at prosedyrene for et gitt statistisk eksperiment er festet på plass før eksperimentet starter, og forblir uendret til eksperimentet avsluttes.
4) Clustering - som kan forventes selv i helt tilfeldige data.
Vurder en medisinsk studie som undersøker hvordan en bestemt sykdom, som kreft eller multippel sklerose, er geografisk distribuert. Hvis sykdommen slår tilfeldig (og miljøet ikke har noen effekt), forventer vi å se mange pasientklynger som en selvfølge. Hvis pasientene er spredt helt jevnt, ville fordelingen være mest tilfeldig!
Så nærværet av en enkelt klynge, eller et antall små klynger av tilfeller, er helt normalt. Det er behov for sofistikerte statistiske metoder for å bestemme hvor mye klynging er nødvendig for å utlede at noe i dette området kan forårsake sykdommen.
Dessverre gjør noen klynger - selv ikke en signifikant - en enkel (og ved første øyekast overbevisende) nyhetsoverskrift.

Statistisk analyse, som alle andre kraftige verktøy, må brukes svært nøye - og spesielt må man alltid være forsiktig når man trekker konklusjoner basert på at to mengder er korrelerte.
I stedet må vi alltid insistere på separate bevis for å argumentere for årsak og virkning - og at beviset ikke kommer i form av et enkelt statistisk nummer.
Tilsynelatende overbevisende korrelasjoner, si mellom givne gener og schizofreni eller mellom a høyt fett diett og hjertesykdom, kan vise seg å være basert på svært tvilsom metodikk.
Vi er kanskje som en art som er kognitivt syk forberedt på å håndtere disse problemene. Som kanadisk lærer Kieran Egan legg det i boken hans Får det feil fra begynnelsen:
Den dårlige nyheten er at vår utvikling har gitt oss anledning til å leve i små, stabile, jegere-samlere. Vi er Pleistocene folk, men våre languaged hjerner har skapt massive, flerkulturelle, teknologisk sofistikerte og raskt skiftende samfunn for at vi skal bo i.
Som følge av dette må vi hele tiden motstå fristelsen til å se mening i sjanse og forvirre korrelasjon og årsakssammenheng.![]()
Denne artikkelen ble opprinnelig publisert på Den Conversation
Les opprinnelige artikkelen.
Om forfatterne
 Jonathan Borwein (Jon) er Laureate Professor i matematikk ved University of Newcastle. Han er Laureate Professor i matematikk ved University of Newcastle og direktør for Senter for Computer Assisted Research Mathematics og dets applikasjoner (CARMA). Han har jobbet i Carnegie-Melon, Dalhousie, Simon Fraser og Waterloo Universities, og har holdt to Canada Research Chairs i databehandling.
Jonathan Borwein (Jon) er Laureate Professor i matematikk ved University of Newcastle. Han er Laureate Professor i matematikk ved University of Newcastle og direktør for Senter for Computer Assisted Research Mathematics og dets applikasjoner (CARMA). Han har jobbet i Carnegie-Melon, Dalhousie, Simon Fraser og Waterloo Universities, og har holdt to Canada Research Chairs i databehandling.
 Michael Rose er doktorgradskandidat, Matematisk og Fysisk Fakultet ved Universitetet i Newcastle.Mathematics PhD student under oppsyn av Laureate Prof. Jon Borwein ved University of Newcastle, Australia. Foreløpig assisterer med forskning i bruk fraktal matematikk til modellering hjerne synaps distribusjoner.
Michael Rose er doktorgradskandidat, Matematisk og Fysisk Fakultet ved Universitetet i Newcastle.Mathematics PhD student under oppsyn av Laureate Prof. Jon Borwein ved University of Newcastle, Australia. Foreløpig assisterer med forskning i bruk fraktal matematikk til modellering hjerne synaps distribusjoner.
Opplysningserklæring: Forfatterne arbeider ikke for, konsulterer, eier aksjer i eller mottar finansiering fra firma eller organisasjon som vil ha nytte av denne artikkelen. De har heller ingen relevante tilknytninger.
Anbefalt bok:
Penger, Sex, Krig, Karma: Notater for en buddhistisk revolusjon
av David R. Loy.
 David Loy er blitt en av de mektigste fortalerne til den buddhistiske verdensbilden, og forklarer at ingen andre har evnen til å forvandle det sosiopolitiske landskapet til den moderne verden. I Penger, sex, krig, karma, gir han skarpe og til og med sjokkerende klare presentasjoner av ofte misforstått buddhistiske stifter - Karma, naturens selvstendighet, årsakene til problemer på både de enkelte og samfunnsnivåer - og de virkelige grunnene til vår kollektive følelse av "aldri nok , "om det er tid, penger, sex, sikkerhet ... selv krig. Davids "buddhistiske revolusjon" er ikke mindre enn en radikal forandring i måtene vi kan nærme våre liv, vår planet, de kollektive vrangforestillinger som gjennomgår vårt språk, kultur og til og med vår åndelighet.
David Loy er blitt en av de mektigste fortalerne til den buddhistiske verdensbilden, og forklarer at ingen andre har evnen til å forvandle det sosiopolitiske landskapet til den moderne verden. I Penger, sex, krig, karma, gir han skarpe og til og med sjokkerende klare presentasjoner av ofte misforstått buddhistiske stifter - Karma, naturens selvstendighet, årsakene til problemer på både de enkelte og samfunnsnivåer - og de virkelige grunnene til vår kollektive følelse av "aldri nok , "om det er tid, penger, sex, sikkerhet ... selv krig. Davids "buddhistiske revolusjon" er ikke mindre enn en radikal forandring i måtene vi kan nærme våre liv, vår planet, de kollektive vrangforestillinger som gjennomgår vårt språk, kultur og til og med vår åndelighet.
Klikk her for mer info og / eller å bestille denne boken på Amazon.



















